
在錯綜復雜的城市監控網絡中,如何從數百個攝像頭、數千小時的視頻中快速鎖定目標?面對嫌疑人距離攝像頭較遠、光線較暗、遮擋甚至混入人群的復雜場景,傳統視頻偵查是否已力不從心?絕影V3.0攜自研ReID大模型重磅升級,以AI大模型破解跨鏡追蹤難題,讓“隱身”的嫌疑人無所遁形!

ReID傳統模型三大局限
特征泛化力弱:
依賴有限場景數據,跨攝像頭適應性差;
細節捕捉不足:
局部特征(如背包、鞋款)易被環境干擾淹沒;
魯棒性不足:
遮擋、低光照等極端場景下性能驟降。
ReID大模型三大技術飛躍
面向公共安全領域等重大需求,多維視通聚焦行人目標,構建監控場景ReID大模型,利用海量監控場景數據構建基礎數據集,基于人體先驗結構信息指導自監督模型預訓練,并深入挖掘行人多重語義信息,高質量完成多種行人相關的下游多模態任務。
新一代的ReID大模型在自有監控場景測試集泛化準確率提升15%以上,并在多個實際案件數據測試中效果顯著,表明該模型的升級,實現了三大技術飛躍:
特征提取更精準
自研多模態融合算法,綜合人體姿態、步態、局部細節(如背包、配飾)等20+維度特征,即使目標換裝仍能通過鞋款、背包等細節精準鎖定;
復雜場景更魯棒
對抗訓練技術強化模型抗干擾能力,低光照、高密度、多角度等極端場景下識別率提升40%;
自監督學習賦能
利用無標注數據挖掘潛在特征關聯,減少對標注數據的依賴,模型泛化性大幅增強。
實戰案例
某地案件中,嫌疑目標活動范圍較廣,涉及20多個攝像頭,其中部分攝像頭下,目標距離攝像頭較遠,目標分辨率小,且存在模糊情況。使用ReID傳統模型,此類目標排前率較低。使用絕影V3.0的ReID大模型進行檢索,前30均是該目標,目標在20多個攝像頭下出現的影像一次全部檢出。

REID傳統模型結果
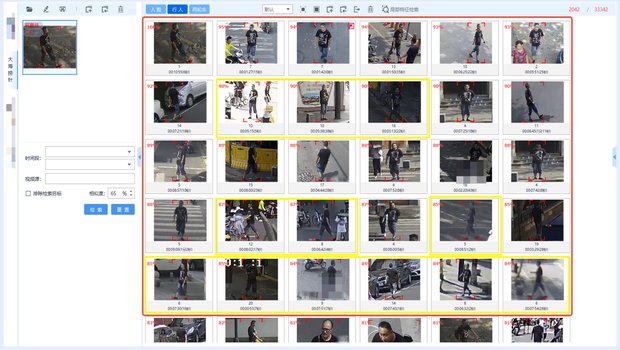
REID大模型結果
注:紅框為檢索出的目標,黃框為分辨率小、模糊等目標。結語
總結:
我們深知,一線偵查需要的不僅是技術參數的提升,更是對復雜場景的精準適應、對實戰痛點的真正解決。ReID大模型以海量數據為基、以調優訓練為翼、以多特征融合為刃,讓AI不再是實驗室中的理想化模型,而是真正成為民警手中“看得清、追得準、判得明”的實戰利器。
未來,絕影將繼續以技術扎根實戰,以創新驅動變革,讓每一次追蹤都精準可靠,讓每一幀影像都釋放價值,讓每一個視頻數據都能轉化為守護安全的堅實力量。
技術為矛,安全為盾
——絕影V3.0與您共同守護每一寸城鄉安全。


